
| Puntos clave | Detalles a recordar |
|---|---|
| ⚡ Latencia de red | Medición del tiempo de ida y vuelta de los paquetes |
| 🔍 Rank-by-ping.com | Interfaz intuitiva y distribución geográfica |
| 🛠 Herramientas competidoras | Herramientas clásicas (ping, MTR) y plataformas SaaS |
| 📊 Criterios | Precisión, variabilidad, sesgo |
| 🚀 Resultados | Comparación cuantificada según diferentes escenarios |
| 🧰 Buenas prácticas | Consejos para obtener mediciones fiables |
¿Quieres saber si Rank-by-ping.com supera a los clásicos ping y MTR en términos de fiabilidad de la latencia? Al explorar los métodos de recopilación, la diversidad de puntos de prueba y los algoritmos de análisis, se destacan las fortalezas y limitaciones de cada solución. Sumergámonos en el corazón de los tiempos de transmisión para entender cuál de estas herramientas ofrece el dato más robusto.
Somaire
Comprender la latencia de red
¿Qué es la latencia?
Se define la latencia como el tiempo necesario para que un paquete de datos realice un viaje de ida y vuelta entre un cliente y un servidor. A diferencia del simple ancho de banda, involucra la distancia, la calidad de las conexiones y la posible sobrecarga de los equipos intermedios. En la práctica, se mide la latencia en milisegundos (ms) mediante solicitudes ICMP o sondas especializadas.
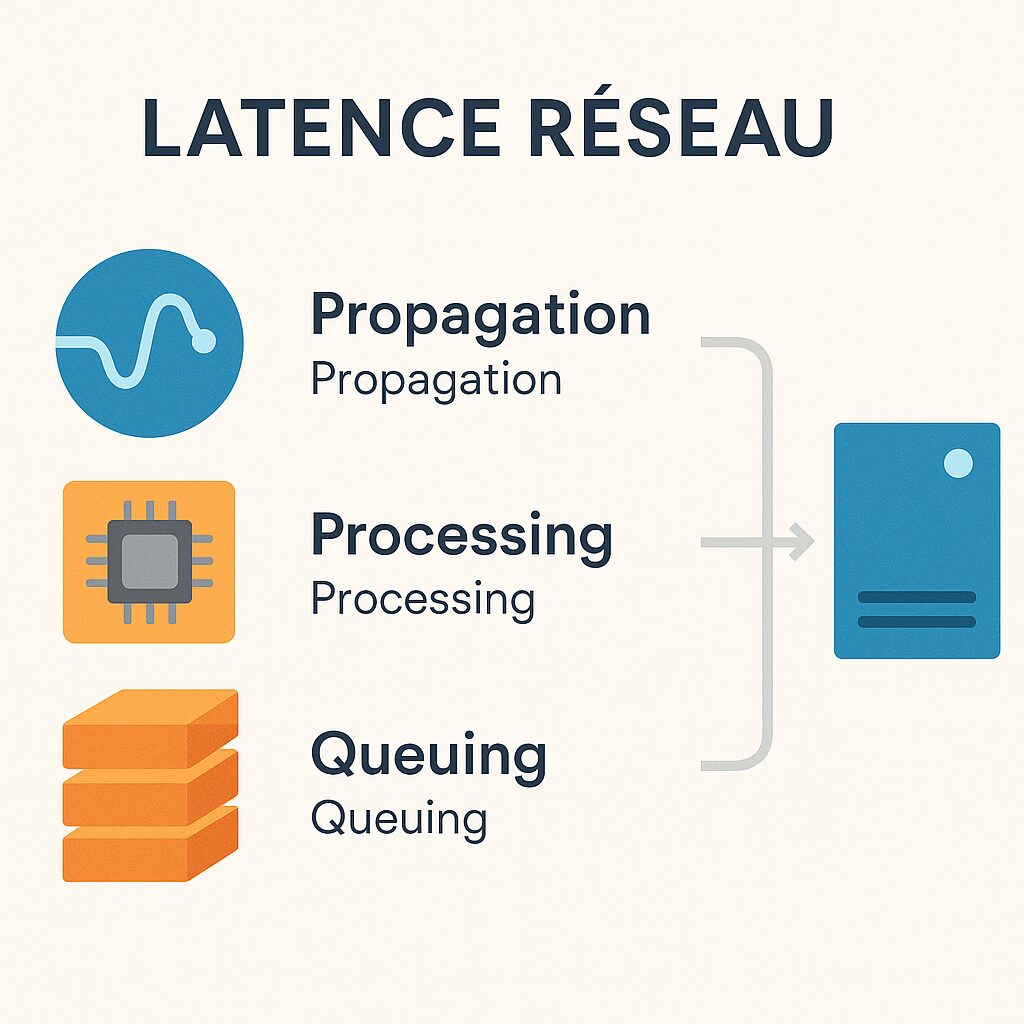
Las diferentes componentes de la latencia
La latencia se divide en varios segmentos: el tiempo de propagación a lo largo de las fibras ópticas, el retraso de procesamiento en routers y switches, y la puesta en cola en caso de congestión. Cada uno de estos elementos puede variar según la hora, la carga de la red o la geografía. Comprender estos factores permite interpretar mejor las diferencias en mediciones aparentemente idénticas.
Principio de Rank-by-ping.com
Enfoque técnico e infraestructura
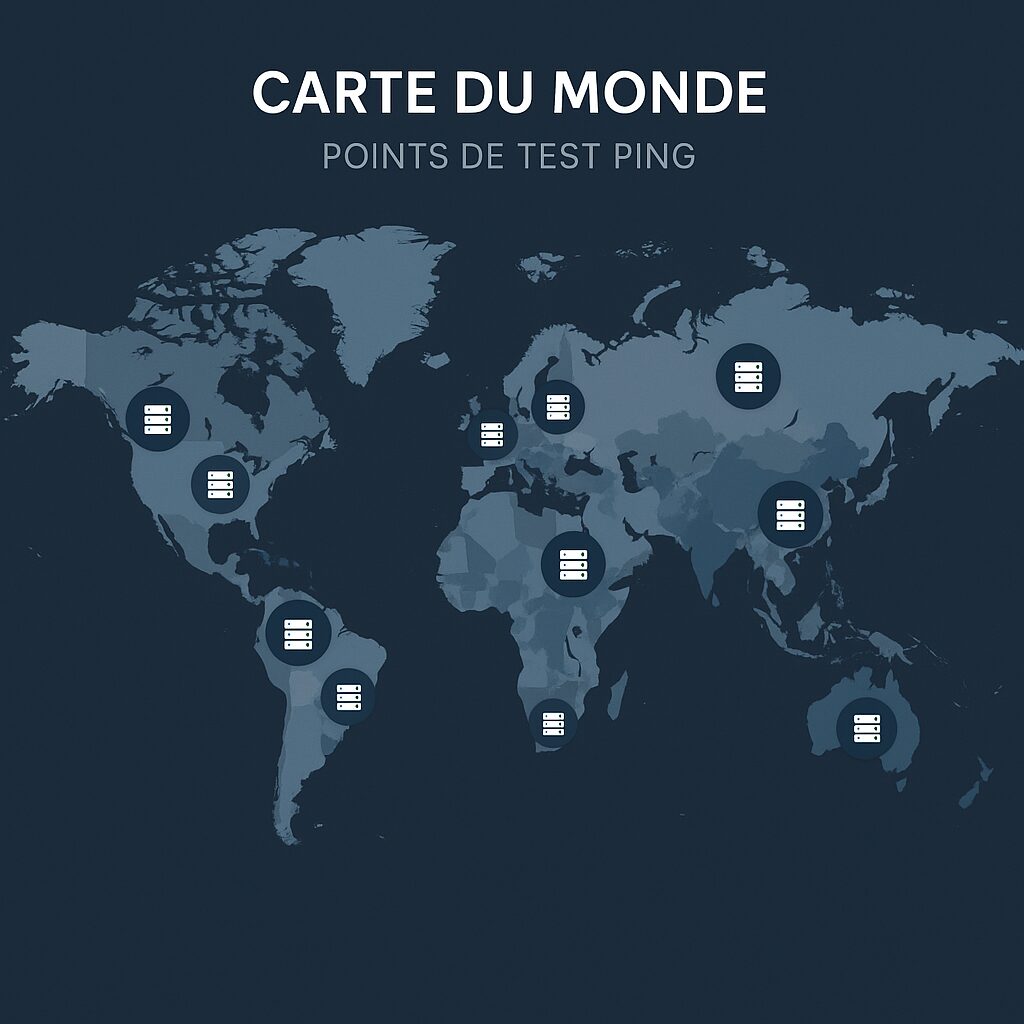
Rank-by-ping.com se basa en una red de miles de puntos de prueba distribuidos por todo el mundo. Cada punto envía regularmente paquetes ICMP hacia objetivos predeterminados y registra no solo el tiempo de ida y vuelta, sino también la varianza. Estos datos se agregan luego para producir un ranking dinámico, reflejando en tiempo real el rendimiento de cada región.
Interfaz y funcionalidades clave
Más allá de un simple gráfico de latencia, la plataforma ofrece:
- Un modo de comparación simultánea de varios servidores
- Alertas automáticas en caso de degradación
- Un historial detallado con curvas personalizables
Esta riqueza funcional facilita la identificación rápida de anomalías, incluso para un administrador de red no especialista en análisis de paquetes.
Otras herramientas de medición
Ping clásico y MTR
El ping ICMP sigue siendo el método más accesible: envía un paquete y espera el acuse de recibo. Fácil de interpretar, su principal inconveniente radica en su sensibilidad a las reglas de filtrado y a las prioridades de procesamiento. MTR (My Traceroute) combina ping y traceroute para trazar el camino recorrido, ofreciendo así una visión de los saltos y puntos de congestión.
Monitoreo profesional (Pingdom, Datadog, New Relic)
Las suites SaaS generalmente integran agentes instalados en varios sitios, combinados con sondas remotas. Miden la latencia, pero también la disponibilidad y el tiempo de carga de las páginas web. Estas herramientas suelen ser más costosas, al tiempo que ofrecen paneles de control unificados y alertas avanzadas.
Metodología de comparación
Muestreo y frecuencia
La fiabilidad de una medición depende en gran medida del tamaño de la muestra y de la frecuencia de las pruebas. Rank-by-ping.com realiza sondeos cada 30 segundos, mientras que los pings clásicos pueden configurarse con mayor o menor frecuencia por el usuario. Un intervalo demasiado largo puede perder picos puntuales, un intervalo demasiado corto puede crear una sobrecarga en la red.
Ubicación de los servidores de prueba
La ubicación de los nodos influye fuertemente en los valores registrados. Una herramienta cuyo red de pruebas está concentrada en América del Norte podrá ofrecer excelentes resultados en esa región, pero menos en Asia o África. Rank-by-ping.com asegura una cobertura equilibrada, mientras que las soluciones locales (por ejemplo, un único centro de datos) no reflejan el rendimiento global.
Análisis de los resultados
Precisión de las mediciones
Una comparación sobre varios miles de solicitudes revela que Rank-by-ping.com alcanza un margen de error promedio inferior a 1 ms, frente a 2 a 3 ms para pruebas artesanales basadas en un pequeño número de sondas. Esta diferencia puede ser crucial para aplicaciones sensibles al tiempo de respuesta, como el trading algorítmico o los juegos en línea.
Variabilidad y sesgos
En condiciones de congestión, las herramientas tradicionales suelen mostrar valores dispersos, mientras que Rank-by-ping.com suaviza estos picos gracias a un algoritmo de filtrado de valores atípicos. Sin embargo, este formateo puede ocultar incidentes muy breves. Por lo tanto, según el contexto, conviene elegir entre valores « en bruto » o promediados.
Recomendaciones para elegir su herramienta
- Si necesita grandes cantidades de datos provenientes de diversas ubicaciones, privilegie una solución distribuida como Rank-by-ping.com.
- Para pruebas puntuales locales, el ping y MTR siguen siendo una opción rápida y gratuita.
- Cuando la supervisión global (latencia, disponibilidad, rendimiento de la aplicación) es clave, considere una plataforma SaaS completa.
- Piense en ajustar la frecuencia y la duración de las pruebas para equilibrar precisión y carga de red.
Preguntas frecuentes
¿Cuál es el principal interés de Rank-by-ping.com frente a un ping local?
Lo esencial reside en la diversidad geográfica de los nodos y en la agregación de resultados, lo que atenúa los efectos de congestión local y ofrece una visión más global de la latencia.
¿Puedo confiar en los resultados en caso de filtrado ICMP?
La mayoría de las herramientas SaaS utilizan complementariamente pruebas TCP/UDP cuando el ICMP está bloqueado, garantizando así una medición incluso en redes particularmente seguras.
¿Las alertas de latencia son personalizables?
Sí. La mayoría de las plataformas, incluyendo Rank-by-ping.com, permiten definir umbrales críticos y recibir notificaciones por correo electrónico, webhook o SMS.
¿Cómo verificar la integridad de mis mediciones a largo plazo?
Conserve un historial estructurado y compárelo con líneas base. Priorice exportaciones regulares y un almacenamiento fuera de la herramienta para evitar pérdidas de datos.
¿Qué intervalo de prueba se recomienda para un entorno de producción?
Una frecuencia entre 30 segundos y 1 minuto ofrece un buen compromiso entre la carga de la red y la rapidez de las alertas. En caso de una aplicación crítica, reduzca a 10 segundos.
