
| Kluczowe punkty | Szczegóły do zapamiętania |
|---|---|
| ⚡ Opóźnienie sieci | Pomiar czasu podróży pakietów w obie strony |
| 🔍 Rank-by-ping.com | Intuicyjny interfejs i dystrybucja geograficzna |
| 🛠 Narzędzia konkurencyjne | Klasyczne narzędzia (ping, MTR) i platformy SaaS |
| 📊 Kryteria | Precyzja, zmienność, stronniczość |
| 🚀 Wyniki | Porównanie liczbowe według różnych scenariuszy |
| 🧰 Dobre praktyki | Wskazówki jak uzyskać wiarygodne pomiary |
Chcesz się dowiedzieć, czy Rank-by-ping.com przewyższa klasyczne ping i MTR pod względem wiarygodności pomiaru opóźnienia? Analizując metody zbierania danych, różnorodność punktów testowych i algorytmy analizy, uwidaczniają się mocne strony i ograniczenia każdego rozwiązania. Zanurzmy się w sedno czasów transmisji, aby zrozumieć, które z tych narzędzi dostarcza najbardziej solidne dane.
Somaire
Zrozumienie opóźnienia sieci
Co to jest opóźnienie?
Opóźnienie definiuje się jako czas potrzebny pakietowi danych na odbycie podróży w obie strony między klientem a serwerem. W przeciwieństwie do samej przepustowości, uwzględnia ono odległość, jakość połączeń oraz ewentualne przeciążenie urządzeń pośrednich. W praktyce opóźnienie mierzy się w milisekundach (ms) za pomocą zapytań ICMP lub specjalistycznych sond.
Różne składniki opóźnienia
Opóźnienie dzieli się na kilka segmentów: czas propagacji wzdłuż światłowodów, opóźnienie przetwarzania w routerach i switchach oraz kolejkę oczekiwania w przypadku przeciążenia. Każdy z tych elementów może się różnić w zależności od godziny, obciążenia sieci lub geografii. Zrozumienie tych czynników pozwala lepiej interpretować różnice w pozornie identycznych pomiarach.
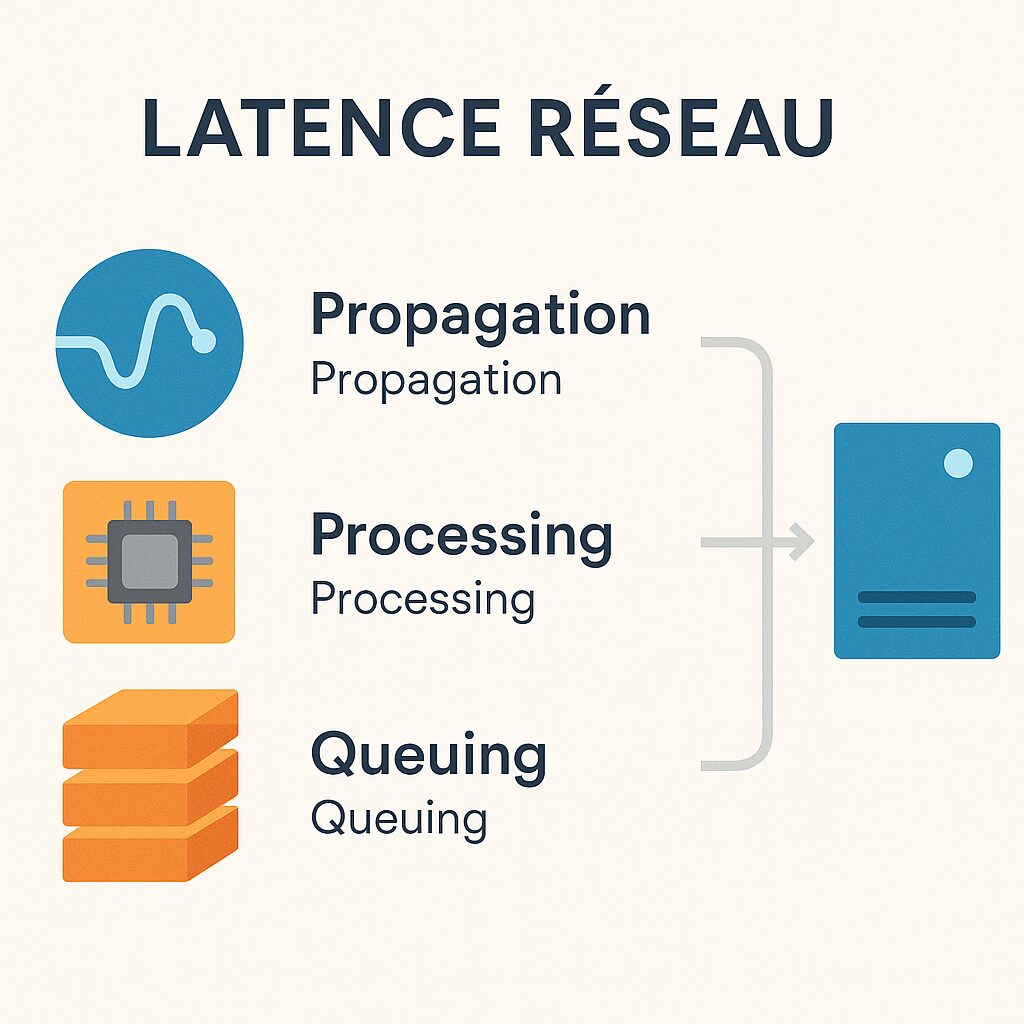
Zasada działania Rank-by-ping.com
Podejście techniczne i infrastruktura
Rank-by-ping.com opiera się na sieci tysięcy punktów testowych rozmieszczonych na całym świecie. Każdy punkt regularnie wysyła pakiety ICMP do zdefiniowanych celów i rejestruje nie tylko czas podróży w obie strony, ale także wariancję. Dane te są następnie agregowane, aby stworzyć dynamiczny ranking, odzwierciedlający w czasie rzeczywistym wydajność każdego regionu.
Interfejs i kluczowe funkcje
Poza prostym wykresem opóźnienia platforma oferuje:
- Tryb porównania wielu serwerów jednocześnie
- Automatyczne alerty w przypadku pogorszenia
- Szczegółową historię z wykresami do personalizacji
Ta funkcjonalna bogactwo ułatwia szybkie wykrywanie anomalii, nawet dla administratora sieci niebędącego specjalistą od analizy pakietów.
Inne narzędzia pomiarowe
Klasyczny ping i MTR
Ping ICMP pozostaje najłatwiejszą metodą: wysyła pakiet i czeka na potwierdzenie odbioru. Łatwy do interpretacji, jego główną wadą jest wrażliwość na zasady filtrowania i priorytety przetwarzania. MTR (My Traceroute) łączy ping i traceroute, aby śledzić trasę pakietu, oferując widok przeskoków i punktów przeciążenia.
Profesjonalny monitoring (Pingdom, Datadog, New Relic)
Pakiety SaaS zazwyczaj integrują agentów zainstalowanych na wielu lokalizacjach, połączonych z sondami zdalnymi. Mierzą one opóźnienie, ale także dostępność i czas renderowania stron internetowych. Narzędzia te są często droższe, oferując jednocześnie zunifikowane pulpity nawigacyjne i zaawansowane alerty.
Metodologia porównania
Próbkowanie i częstotliwość
Wiarygodność pomiaru w dużej mierze zależy od wielkości próbki i częstotliwości testów. Rank-by-ping.com wykonuje sondowania co 30 sekund, podczas gdy klasyczne pingi mogą być konfigurowane przez użytkownika z różną częstotliwością. Zbyt długi odstęp może spowodować pominięcie krótkotrwałych szczytów, zbyt krótki może natomiast generować nadmierne obciążenie sieci.
Lokalizacja serwerów testowych
Położenie węzłów ma duży wpływ na odnotowane wartości. Narzędzie, którego sieć testowa jest skoncentrowana w Ameryce Północnej, może oferować doskonałe wyniki w tym regionie, ale gorsze w Azji czy Afryce. Rank-by-ping.com zapewnia zrównoważone pokrycie, podczas gdy lokalne rozwiązania (np. pojedyncze centrum danych) nie odzwierciedlają globalnej wydajności.
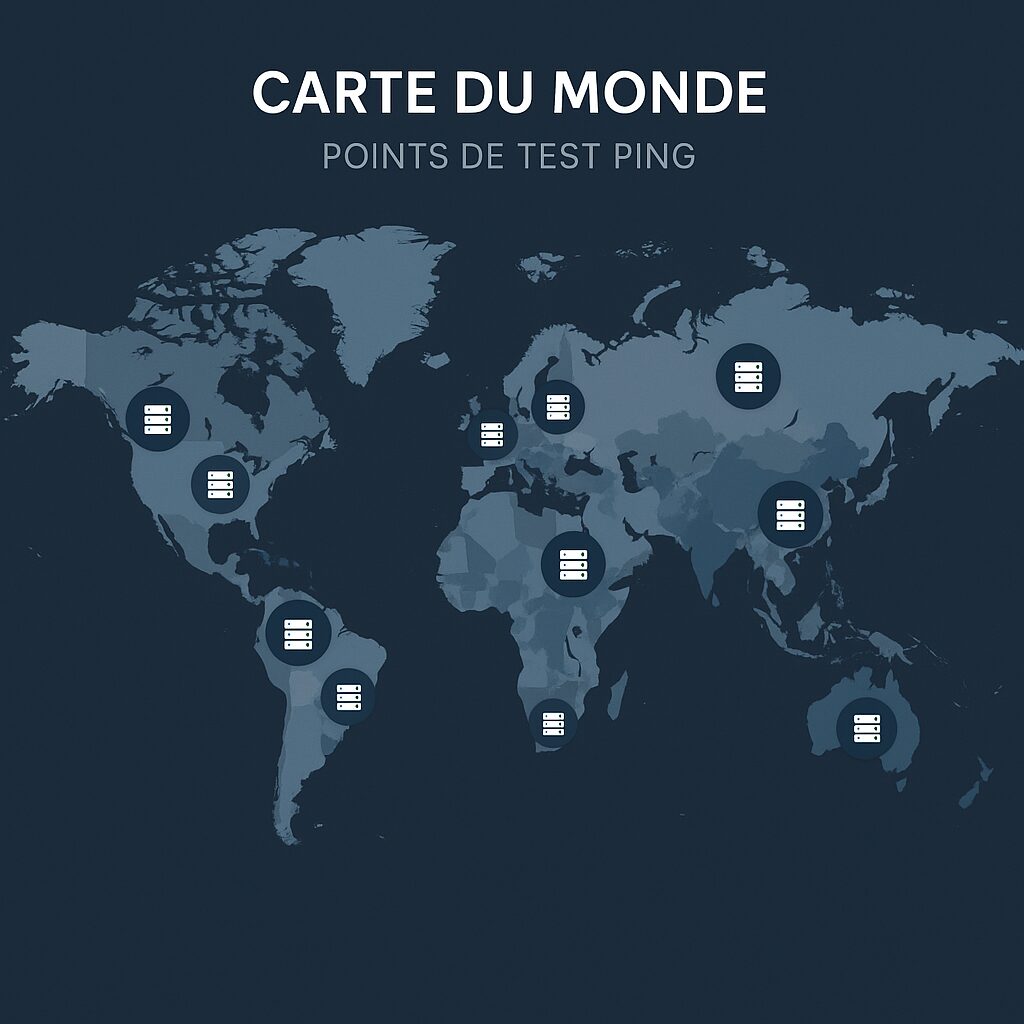
Analiza wyników
Precyzja pomiarów
Porównanie na podstawie kilku tysięcy zapytań wykazuje, że Rank-by-ping.com osiąga średni margines błędu poniżej 1 ms, podczas gdy testy amatorskie oparte na niewielkiej liczbie sond mają błąd rzędu 2 do 3 ms. Ta różnica może być kluczowa dla aplikacji wrażliwych na czas odpowiedzi, takich jak handel algorytmiczny czy gry online.
Zmienne i błędy systematyczne
W warunkach przeciążenia tradycyjne narzędzia często pokazują rozproszone wartości, podczas gdy Rank-by-ping.com wygładza te szczyty dzięki algorytmowi filtrowania wartości odstających. Z drugiej strony, takie formatowanie może ukrywać bardzo krótkie incydenty. W zależności od kontekstu należy więc wybierać między wartościami „surowymi” a uśrednionymi.
Rekomendacje dotyczące wyboru narzędzia
- Jeśli potrzebujesz dużych ilości danych z różnych lokalizacji, wybierz rozwiązanie rozproszone, takie jak Rank-by-ping.com.
- Do jednorazowych testów lokalnych ping i MTR pozostają szybkim i darmowym wyborem.
- Gdy kluczowy jest globalny monitoring (opóźnienie, dostępność, wydajność aplikacji), rozważ pełną platformę SaaS.
- Pamiętaj, aby dostosować częstotliwość i czas trwania testów, aby zrównoważyć precyzję i obciążenie sieci.
FAQ
Jaka jest główna zaleta Rank-by-ping.com w porównaniu z lokalnym pingiem?
Kluczowa jest różnorodność geograficzna węzłów oraz agregacja wyników, co łagodzi skutki lokalnych przeciążeń i daje bardziej globalny obraz opóźnień.
Czy można ufać wynikom w przypadku filtrowania ICMP?
Większość narzędzi SaaS stosuje dodatkowo testy TCP/UDP, gdy ICMP jest blokowane, zapewniając pomiar nawet w szczególnie zabezpieczonych sieciach.
Czy alerty opóźnień są konfigurowalne?
Tak. Większość platform, w tym Rank-by-ping.com, pozwala definiować krytyczne progi i otrzymywać powiadomienia e-mail, webhookiem lub SMS-em.
Jak weryfikować integralność moich pomiarów na dłuższą metę?
Przechowuj uporządkowaną historię i porównuj ją z bazowymi wartościami. Preferuj regularne eksporty i przechowywanie danych poza narzędziem, aby uniknąć utraty danych.
Jaki interwał testowy jest zalecany dla środowiska produkcyjnego?
Częstotliwość między 30 sekundami a 1 minutą stanowi dobry kompromis między obciążeniem sieci a szybkością reakcji alertów. W przypadku krytycznej aplikacji zmniejsz do 10 sekund.
