
| Points clés | Détails à retenir |
|---|---|
| ⚡ Latence réseau | Mesure du délai aller-retour des paquets |
| 🔍 Rank-by-ping.com | Interface intuitive et distribution géographique |
| 🛠 Outils concurrents | Outils classiques (ping, MTR) et plateformes SaaS |
| 📊 Critères | Précision, variabilité, biais |
| 🚀 Résultats | Comparaison chiffrée selon différents scénarios |
| 🧰 Bonnes pratiques | Conseils pour obtenir des mesures fiables |
Vous cherchez à savoir si Rank-by-ping.com surpasse les classiques ping et MTR en termes de fiabilité de la latence ? En explorant les méthodes de collecte, la diversité des points de test et les algorithmes d’analyse, on met en lumière les forces et les limites de chaque solution. Plongeons au cœur des délais de transmission pour comprendre lequel de ces outils livre la donnée la plus robuste.
Somaire
Comprendre la latence réseau
Qu’est-ce que la latence ?
On définit la latence comme le temps nécessaire à un paquet de données pour effectuer un aller-retour entre un client et un serveur. Contrairement au simple débit, elle met en jeu la distance, la qualité des liaisons et la surcharge éventuelle des équipements intermédiaires. En pratique, on mesure la latence en millisecondes (ms) à l’aide de requêtes ICMP ou de sondes spécialisées.
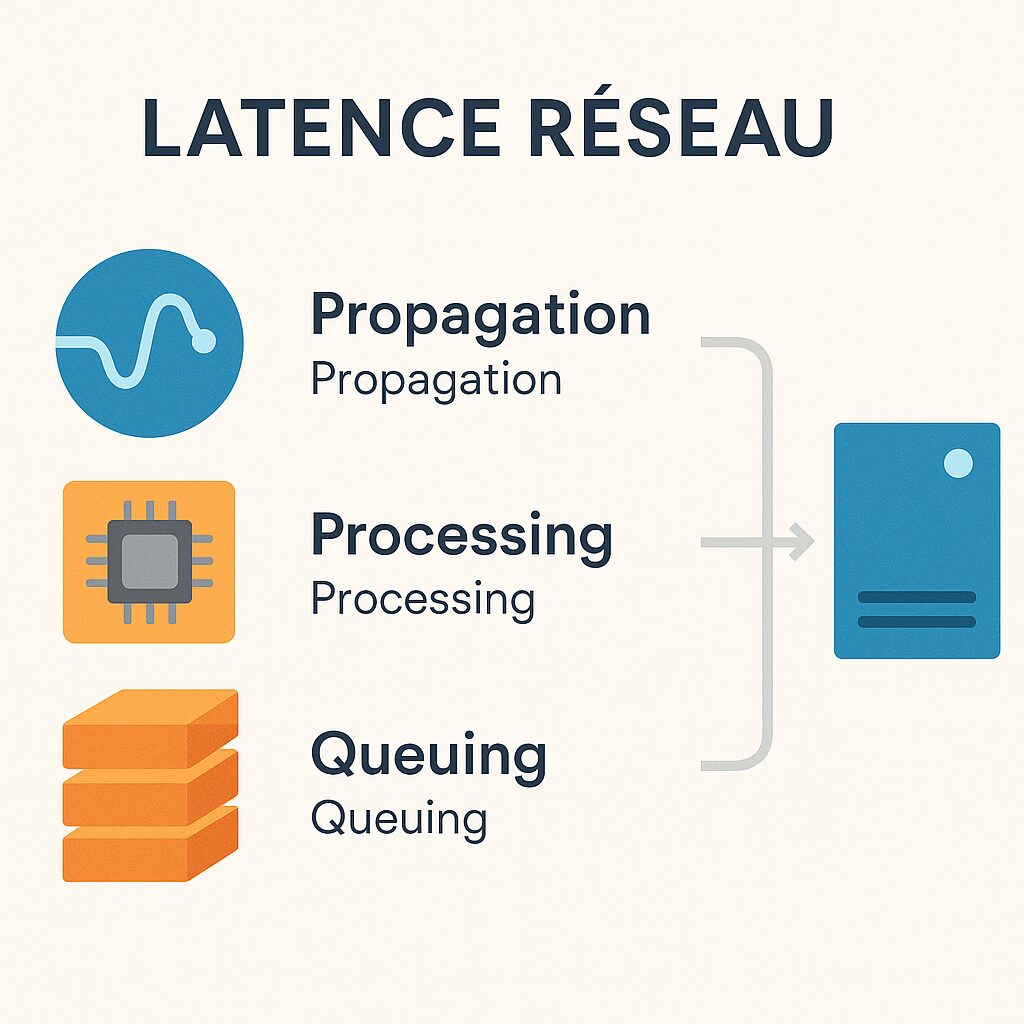
Les différentes composantes de la latence
La latence se découpe en plusieurs segments : le temps de propagation le long des fibres optiques, le délai de traitement dans les routeurs et switchs, et la mise en file d’attente en cas de congestion. Chacun de ces éléments peut varier selon l’heure, la charge du réseau ou la géographie. Comprendre ces facteurs permet de mieux interpréter des écarts sur des mesures apparemment identiques.
Principe de Rank-by-ping.com
Approche technique et infrastructure
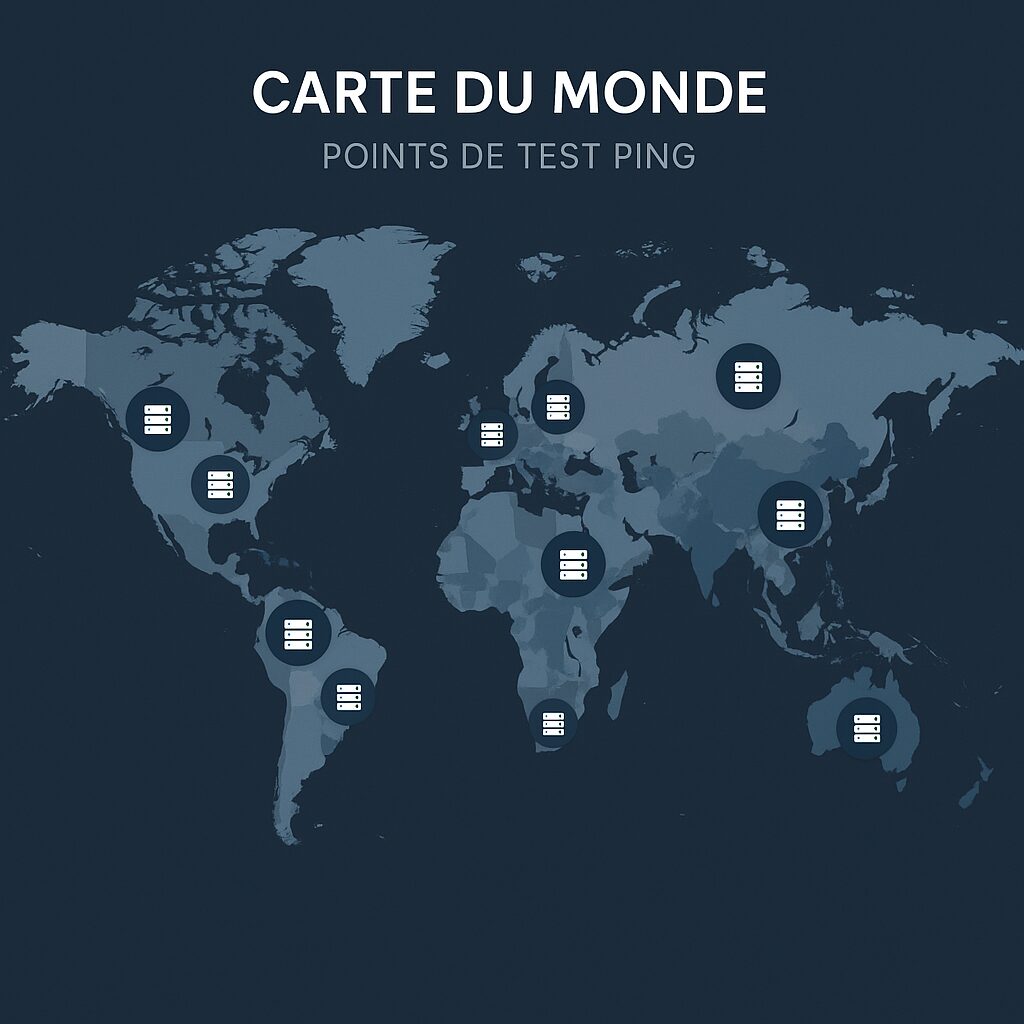
Rank-by-ping.com repose sur un réseau de milliers de points de test répartis dans le monde entier. Chaque point envoie régulièrement des paquets ICMP vers des cibles prédéfinies et enregistre non seulement le délai aller-retour, mais aussi la variance. Ces données sont ensuite agrégées pour produire un classement dynamique, reflétant en temps réel les performances de chaque région.
Interface et fonctionnalités clés
Au-delà d’un simple graphique de latence, la plateforme propose :
- Un mode comparaison simultanée de plusieurs serveurs
- Des alertes automatiques en cas de dégradation
- Un historique détaillé avec courbes personnalisables
Cette richesse fonctionnelle facilite l’identification rapide d’anomalies, même pour un administrateur réseau non spécialiste en analyse de paquets.
Les autres outils de mesure
Ping classique et MTR
Le ping ICMP demeure la méthode la plus accessible : il envoie un paquet et attend l’accusé de réception. Simple à interpréter, son principal inconvénient réside dans sa sensibilité aux règles de filtrage et aux priorités de traitement. MTR (My Traceroute) combine ping et traceroute pour tracer le chemin parcouru, offrant ainsi une vision des sauts et des points de congestion.
Monitoring professionnel (Pingdom, Datadog, New Relic)
Les suites SaaS intègrent généralement des agents installés sur plusieurs sites, couplés à des sondes distantes. Elles mesurent la latence mais aussi la disponibilité et le temps de rendu des pages web. Ces outils sont souvent plus coûteux, tout en proposant des tableaux de bord unifiés et des alertes avancées.
Méthodologie de comparaison
Échantillonnage et fréquence
La fiabilité d’une mesure dépend largement de la taille de l’échantillon et de la cadence des tests. Rank-by-ping.com réalise des sondages toutes les 30 secondes, tandis que les pings classiques peuvent être configurés plus ou moins fréquemment par l’utilisateur. Un intervalle trop long risque de manquer des pics ponctuels, un intervalle trop court peut créer une surcharge réseau.
Localisation des serveurs de test
L’emplacement des nœuds influe fortement sur les valeurs relevées. Un outil dont le réseau de tests est concentré en Amérique du Nord pourra offrir d’excellents résultats dans cette région, mais moins en Asie ou en Afrique. Rank-by-ping.com assure une couverture équilibrée, alors que les solutions locales (ex. un datacenter unique) ne reflètent pas la performance globale.
Analyse des résultats
Précision des mesures
Un comparatif sur plusieurs milliers de requêtes révèle que Rank-by-ping.com atteint une marge d’erreur moyenne inférieure à 1 ms, contre 2 à 3 ms pour des tests artisanaux basés sur un petit nombre de sondes. Cette différence peut s’avérer cruciale pour les applications sensibles au temps de réponse, comme le trading algorithmique ou les jeux en ligne.
Variabilité et biais
En conditions de congestion, les outils traditionnels affichent souvent des valeurs éclatées, tandis que Rank-by-ping.com lisse ces pics grâce à un algorithme de filtrage des outliers. En revanche, cette mise en forme peut masquer des incidents très courts. Il convient donc, selon le contexte, de choisir entre valeurs « brutes » ou moyennées.
Recommandations pour choisir son outil
- Si vous avez besoin de grandes quantités de données issues de divers emplacements, privilégiez une solution distribuée comme Rank-by-ping.com.
- Pour des tests ponctuels en local, le ping et MTR restent une option rapide et gratuite.
- Lorsque la surveillance globale (latence, disponibilité, performance applicative) est clé, envisagez une plateforme SaaS complète.
- Pensez à ajuster la fréquence et la durée des tests pour équilibrer précision et charge réseau.
FAQ
Quel est l’intérêt principal de Rank-by-ping.com par rapport à un ping local ?
L’essentiel réside dans la diversité géographique des nœuds et dans l’agrégation des résultats, ce qui atténue les effets de congestion locale et offre une vision plus globale de la latence.
Puis-je faire confiance aux résultats en cas de filtrage ICMP ?
La plupart des outils SaaS utilisent en complément des tests TCP/UDP quand l’ICMP est bloqué, garantissant ainsi une mesure même sur des réseaux particulièrement sécurisés.
Les alertes de latence sont-elles personnalisables ?
Oui. La plupart des plateformes, dont Rank-by-ping.com, permettent de définir des seuils critiques et de recevoir des notifications via e-mail, webhook ou SMS.
Comment vérifier l’intégrité de mes mesures sur le long terme ?
Conservez un historique structuré et comparez-le à des baselines. Privilégiez des exports réguliers et un stockage hors de l’outil pour éviter les pertes de données.
Quel intervalle de test est recommandé pour un environnement de production ?
Une fréquence entre 30 secondes et 1 minute offre un bon compromis entre charge réseau et réactivité des alertes. En cas d’application critique, descendez à 10 secondes.
